AI for Enterprises. Part 2: Metrics for Matriculates? [Extended version]
The recent wave of new opportunities to transform enterprise productivity, innovation and success leveraging artificial intelligence (AI) as part of digital transformation is driven by the tremendous advances in our ability to collect, operate on and extract knowledge from extremely large volumes of data. If not used with adequate care and caution this rapidly evolving opportunity currently comes with catastrophic implications for the enterprise that will be hard to course correct by throwing resources at.
In the first of this two part post on adoption of artificial intelligence in enterprises 'AI for Enterprises. Part 1: Where are we in tackling the popular adage GIGO?' posted in the MassTLC website and the extended version at ReSurfX website, we dealt with various aspects of data quality effects on digital transformation in the context of the popular adage garbage-in-garbage-out (GIGO). In this second installment (Part 2) of this post ‘AI for Enterprises: Metrics for Matriculates?’ also posted in the MassTLC website the theme centers on the power and pitfalls in the use of metrics from and for AI and machine learning (ML) based solutions. This is an extended form of the second part of the post and includes a powerful use case in the healthcare sector using ReSurfX solutions and the enterprise SaaS product ReSurfX::vysen. I highlight common problems in use of metrics and possible solutions that span beyond technical aspects to include enterprise architecture, culture and education appropriate to different organizational divisions and roles in leveraging these multi-disciplinary advances.
Significant portion of what I share here is guided by experiences, observations and inferences often through my lens as the leader of the outcomes intelligence technology company ReSurfX, with a primary focus on the healthcare sector. I take this opportunity to thank the ReSurfX team and variety of experts and leaders who contribute directly or from the sidelines shaping growth of ReSurfX and me.

AI, machine learning (ML) and other aspects that constitute the digital transformation have passed the tipping point and is becoming pervasive part of the society and is an absolute need for most enterprises. The powerful prediction and analytics solutions offered by ReSurfX as an outcomes intelligence suite to improve enterprise innovation and productivity from data-intensive operations through our SaaS product ReSurfX::vysen provide incredible robustness of outcome and value and to our customers. ReSurfX does this in significant part by leveraging a novel data-source agnostic machine learning approach Adaptive Hypersurface Technology (AHT) we invented to overcome many challenges posed by GIGO and use of metrics that are the central themes in these two posts of this series and many others needs for effective utilization of large volumes of data.
AI And Metrics: The Silver Bullet for Enterprise Transformation to Reap Enormous Value That Is Also an Extreme Hazard That Can Fail the Best
Most of us have heard the phrase in some form that ‘any decision that is not supported by data is a guess or opinion’, so in data-driven decisions using that phrase as a norm is a great goal to strive for. While the day we can completely support that phrase will be awesome, the phrase currently preaches an extreme that undermines the power of human brain in contextualization as well as using experiential and accumulated knowledge. At this time the insights generated from digital advances significantly trail the power of human brain, knowledge and experiential power (that cannot be replaced in the near future). However, the ability of the digital advances to gather and crunch enormous amount of information and infer complex insights, beyond the capabilities of the most humans can uniquely enhance brain power and experiential knowledge. The previous fact on the complex interactions on so many parameters that these advances can infer from makes it a double-edged sword - i.e., difficult to parse and achieve otherwise, but often difficult to validate or reliably select the right approaches to predict outcome so can lead to expensive failures and/or significant loss in effort and time.
Having highlighted reasons for and against absolute reliance on need for specific data to support a decision, let us look at how we tap the digital advances to our advantage rather than let them be become metaphorical a ‘red herring’ sending teams and enterprise chasing wrong leads. Emerging experts in ML and AI or quantitative disciplines in general are trained to evaluate approaches using metrics, many of these metrics have been around for a long time.
The key tool (if you allow me to trivialize that need) by which we can communicate the power and reliability of what we get from data-driven insights is through metrics. Metrics in this context could be from and for AI and ML based solutions that you develop, provide or ingest as business and technical leaders and/or experts for effectively achieving enterprise goals and expansion of digital transformation. We highlight opportunities and challenges spanning beyond technical aspects to include enterprise architecture, culture, and education on this multi-disciplinary advance appropriate to different roles.
We have always relied on metrics to help us have standards to measure our progress or lack thereof. In the same vein they can help us leverage the advances in data-driven ML and AI solutions to catapult us forward, however in this case they can be equally misleading and perilous. Some of the reasons for that are: the multidisciplinary nature, continuing rapid evolution and the need for an educative phase tailored for each role to maximize business value, the fact that we emphasized multiple times in the previous post.
The approaches we take at ReSurfX to overcome these problems include:
-
- Reducing or understanding excess reliance on classical quantitative metrics as a measure of functional value.
- Incorporating the concepts on which classical metrics are built on to build our own metrics that are more appropriate for functional end-use.
- Building processes and value differentiation approaches driven by need to solve the problems we observed to be prevalent and failure of classical approaches to solve them.
-
- As we highlighted in previous post of this series and many other prior opportunities including the article published in conjunction with being recognized by the CIO Review Magazine as 20 Most Promising Analytics Solution Providers in 2017 we posited that:
“Dramatic improvements in accuracy and novel insights can only happen through innovation outside the mainstream framework – given that error properties are often non-uniform in big data, and most analytic shortcomings result from model assumptions not robust enough to handle that.” [CIO Review, 2017].
The novel machine learning approach Adaptive Hypersurface Technology ReSurfX leverages in solutions and value we provide to our stakeholders was invented by us, with motivations that include those mentioned above.
The Success of Digital Transformation Critically Depends on the Invisible Innovation Killer Layer of Enterprise Structure
The cost of reaping the advantages from data, ML and AI that is evolving rapidly to become trivial currently seems far away as is the ability to pick approaches that perform uniformly well with reliability.
Naturally, not everyone would, should or could want to or need to become an expert in ML or AI – but the need to be reasonably informed in aspects of this advance that matter to their role is becoming a requirement.
Given these, most enterprises by construct, size, architecture or culture often ends up with what I describe below as an invisible ‘Innovation Killer Layer’. Guarding against this layer (which is no easy feat) by itself can significantly insulate an enterprise against these pitfalls and play a key role in utilizing the potential of digital advances. Many transitive and pseudo-AI product and service companies (that we alluded to in the previous post) use flaws in this layer typical of most target enterprises constructs to design their offerings, as well as to design their sales strategy – i.e., articulate validation, extensibility and value of their offering.
I try to give an outline of the Innovation Killer Layer which is a complex enterprise construct using a far simplified structure. All enterprises are supported by a variety of the allied divisions besides those that are formed with expertise that represent their mainstream focus. The former are typically divisions based on well-established expertise/disciplines (IT layer is an excellent example of former). Now management decides to double down and rapidly build up capabilities for digital transformation, establish AI/ML division as an essential part of that operation not wanting to be late or leave the opportunities behind. Often this division is setup with lot more resources and power. Needless to say, funding to a division and power to the members is considered proportional to priorities of the business leadership team. Unlike other allied sectors this division is anchored on a relatively new rapidly evolving advance with mixed bag of success. If we assume AI/ML is not part of the primary focus sector of the enterprise, this division has to understand the needs and integrate with core function divisions among others. The leaders of this new division have the need to prove their capability and value while adapting to rapid evolution to neither underequip nor build up capabilities that will become obsolete at the next stage of evolution that is not far away. Very few people are highly experienced in leading this class of division and also have sufficient sector specific knowledge or prior success relevant to most sectors that could be reliably be translated into the success and integration. Their team members, however talented, often use approach of matriculates – adhering to established principles – we use metrics to highlight the effect of that approach in this post.
Though all divisions are equally important from operation and efficiency perspectives of the enterprise, sector specific enterprises divisions based on core knowledge of the sector are the back bone of the business. These sector subject matter experts (SMEs) and the core divisions of the enterprise like any other members or divisions are also pressed for results and need to contribute rapidly to the ROI. However, unlike the newly formed AI/ML division, they do not get the slack period.
The new AI/ML division with high matriculate like approach in order to develop and evaluate solutions now reaches out to a core needs division for ground truth. In reality such ‘ground truth’ do not exist in easy to ingest form or are quite nuanced. The leaders or team members of that division having their own targets to accomplish provide data from the past in their specialty for use as ‘ground truth’, stressing that many caveats come with that. The team members of the data science and ML bucket take the ‘ground truth’ (sic) and develop solutions and evaluate their model or algorithmic performance based on that. The real value of those metrics of model or algorithmic performance including due to above reasons significantly differs from those of true functional and business need. Results based on these metrics get insufficiently discussed, as few team members want to create a ruckus, which it will become if they elaborate in the time bound meetings of fast-paced enterprises, and those results in turn are now evaluated as metric for success in gearing for the digital transformation effectively. The whole enterprise often becomes embedded with this additional layer of compromise and the cycle continues. The impact of this will take some time to become evident, by which time most enterprises have paid the price in many ways including of culture, and often the plausible solution might be limited to get to another compromise solution.
Another manifestation of this construct that I am aware of is the mid-level leadership and members in the new interdisciplinary divisions of the enterprise having to establish their need, contribution and value explicitly saying or implicitly practicing ‘what you do/offer is competitive to what I do so I won’t collaborate with you’ to resources with overlapping expertise. In reality the person, entity, division or vendor on the receiving side of this behavioral response strengthens both this new division and the enterprise. The ones on the receiving end could never openly express their perception of insufficient value or contribution of the new division.
After all, most enterprises are not fond of teams or team members who would ‘rock the boat’ by complaining or ‘seemingly questioning’ an initiative highly coveted by the top management. We have recently seen this to be true by even in enterprise like Google, that tend to hire incredibly talented people with an expected trait of hires to be willing to speak openly to management of problems, getting into problems multiple times. The latest is when their CEO had to ‘kind of’ apologize by communicating ‘I accept the responsibility of working to restore your trust’ to his staff after the recent incident with their ML team member.
So the mid-level leaders that the enterprise depend on, who in reality are also the innovators with immense functional knowledge and know how to apply that knowledge towards the goals of the enterprise, form the Innovation Killer Layer in this scenario due to inadequate education, by necessity of governance, enterprise construct or circumstance.
Both examples above are results of insufficient thought into enterprise architecture, messaging about the new division, and time it takes to educate the new division and existing divisions (and probably the rest of the enterprise, starting with leadership) to collaborate on such multi-disciplinary and evolving opportunity. It also ties back to the fact that large amounts of resources invested in that division is usually perceived as a signal of high priority to the management.
I am aware of at least one other extremely different approach a subset of enterprises take where the end effect is equally inefficient. However, discussing other scenarios or the solution to this problem of enterprise architecture is beyond the scope of this post.
In contrast to title of this section, enterprises should avoid the Innovation Killer Layer in order to be successful in setting up or doubling down on expansion of the AI efforts part of digital transformation. While many aspects lead to this effect, improper use of classical metrics and the mindset that are focus of this post serves as a powerful example. Further, this effect and need to avoid it are not restricted to digital transformation, but to most new multi-disciplinary initiatives that are significantly outside the core discipline that drives the enterprise offering(s). This is also a really hard enterprise structure design and maintenance challenges. Even if an enterprise is not resource limited, the cultural effects of getting this wrong cannot be easily corrected post hoc.
How Can Metrics That by Definition Are The Core of Oracle for Performance and Value Become a Cause For Pitfall?
This topic and need again involves a complex mélange of people with different expertise in technical, functional, business and leadership treading across the boundary of disciplines and sensibilities. Here I am taking the approach of enumerating some of those factors followed by use case example that should help take these points in perspective.
- Multi-disciplinary nature of digital transformation (as we repeatedly highlighted in different context) and insufficient preparation of teams across organizational hierarchy and functional roles.
- No absolute ‘ground truth’ (or an oracle we can rely on) for most complex real-life problems
- Not using the right metrics appropriate to an enterprise need – often due to lack of knowledge spanning more than one discipline required for that enterprise need.
- Lack of classical metrics designed for such complexity.
This particular aspect became starkly obvious from fields that entered the digital wave later (e.g., life sciences and healthcare) – where one can see many thousands (if not tens of thousands) articles on approaches to reduce errors and adopting approaches and metrics that do not translate to true value they indicate and often are not robust enough across datasets even from the same platform they are developed for. I believe these aspects are not unique for those fields but became obvious as because they became digitized later and the field has a culture that encourages (often mandates) publications at far higher rate than most other disciplines. To this day this problem is not solved and the culture inherently prevents acceptance of new metrics. One extensive analysis where we documented this property extensively even in a simple case is in a whitepaper in ReSurfX website: ‘Many Roads to Reproducibly Wrong Results - Distinguishing the Truth Using ReSurfX::vysen and Other Analytic Workflows’.
- Problems with data violating the basis of those metrics. Examples include effect of bias embedded in data or non-uniform properties in large data volumes this advance (AI/ML) is built on.
- Definition of outcomes. Often the improvement in AI/ML is defined by metrics that are more theoretical or on assumptions of ground truth for measurement of outcome – so there is a mismatch between what the metric reports versus the practical business goals.
- Generation approach of results also leads to incorrect metrics that misrepresent or not rigorous enough and more importantly not robust enough. This aspect needs particular attention, as this is part of the trick used by whom I referred to as transitive vendors earlier.
- We referred to cases where significant assumptions and solutions with errors can still lead to great business outcomes in the “glass less than half full” section of the previous post as has been the case with great innovations that we rely on in our daily lives. So using approaches with reliance of practical value in validation than matriculate approach as we have been stressing in this post is more useful. This takes effort on the part of the end users and their leaders - there is difference in scope between the two sets of people even with the same enterprise goal.
- Related to the previous point, the value of improvement from new correct predictions/insights should far exceed the error rate.
- Metrics not sufficiently evaluated in practical business context – e.g., bigger decisions (as in enterprise value vs cumulative effect for errors with lower cost. Conversely (to latter part) – small, but reliable and robust improvements repeatedly applied process can lead to large savings in many different ways.
A key take-away from enormous amount of work done at ReSurfX evaluating information in the world is that in the context of practical use: well-designed validations highlighting reliability, robustness and extensibility for real-world applications that the enterprise is engaged in are far more valuable than relying on most classical metrics. Before we get to an example derived using novel advances in technology, functional solutions and products to deliver those solutions built by ReSurfX, I summarize the breadth we covered aimed at the various levels of enterprise hierarchy and knowledge differences of this multidisciplinary advance.
Concluding Thoughts on Successfully Leveraging Data, AI and ML as Part of Digital Transformation and A Powerful Example of Result involving Themes Discussed in This Post
In conclusion, between the two posts we covered several aspects affecting enterprise adoption of digital transformation. We particularly focused on the recent wave and rapidly evolving theme of AI solutions that primarily resulted from advances in our ability to collect and organize very large volumes of data and utilize them to collect insights and build business value that are becoming pervasive in our everyday life. We focused equally on the potential and immense risk that comes with the current state of these solutions in the context of effective adoption and deployment decisions while staying protected from disastrous consequences. Reminding oneself of the state of AI is as simple as recollecting our experience in engaging with voice or chat bots that are the first line of responders when you contact many vendors with some non-trivial need; or recalling how your pictures are identified or sorted by the apps from top enterprises. The two uses in the previous statement are built on the most advanced aspects of this AI wave – image analysis, voice and natural language processing.
I want to share with you one mindset that helps in effective use of Big Data initiatives and these advances centered on them using two statements that we often use at ReSurfX:
An error rate of 1/1000 of data or decisions introduces a terabyte of errors with a petabyte of data.
In large and complex enterprise operations the effect of errors are cumulative in the workflow and errors from early operations often cost you more downstream and could even balloon into a catastrophic event.
The farther along development of a product or offering that needs a long development process or insight generation phase, the larger are the impact of such errors. Not to say that it could be of any less consequence when unreliable (or improper metric of reliability) insights are used in bread and butter steps of each phase or division resulting in wasted resources and time that gets cumulative.
At ReSurfX we build solutions for both classes of needs mentioned in the previous paragraph with practicality of real-life needs, often generating our own measure of confidence than simply using classical metrics. When building functionalities or broadly applicable core modules leveraging differentiated approaches such as the novel Adaptive Hypersurface Technology we invented, our customer value equation integrates these two components (GIGO, metrics) as well as aspects I covered in different contexts as key needs for reliable, accurate and robust AI functionalities. We deliver these as outcomes intelligence solutions through the SaaS platform product ReSurfX::vysen. Recently we have developed an application configuration ‘SyRTOP’ (Systems Response based Triggers and Outcomes Predictor) by combining different stages of assembling and processing these datasets with a combination of AHT based analytics and prediction solutions we developed to get to outcomes and end-points of interest.
A powerful and exemplary result achieved by paying attention to the principles discussed in these posts and approaches developed by ReSurfX implemented in the SaaS product ReSurfX:vysen and SyRTOP in the next section of this extended version of this post. The ReSurfX website vysdom section, also has many find many relevant and useful posts and whitepapers.
A version of this post ending at this point is in the Massachusetts Technology Leadership Council (MassTLC) website.
An Exemplary Result Highlighting Accuracy, Robustness and Novelty of Insights from Applying Sensible Principles in Building and Validating AI Solutions
The following example has new details and is modified from the use case example I used in the extended version of the previous installment of this post ‘AI for Enterprises – Part 1: Where are we in tackling the popular Adage GIGO? [Extended Version]’ to highlight additional properties and needs highlighted in this post. Hence, despite being derived from a common use case scenario, both the posts have complementary information.
AHT is data-source agnostic. Developing AI solutions based on that differentiation using a novel machine learning approach needs extensive proof over and above those needed for solutions based on widely used approaches to quantitate the highly differentiated value we provide to our customers. That same fact also necessitated us to compare the results and outcomes against widely used alternative approaches: (i) widely used commercial and based on open source solutions in use for these classes of datasets, as well as (ii) other many modern machine learning and ensemble approaches.
With above perspective as one basis, the beachhead solutions developed using AHT and released as functionalities through the enterprise SaaS product ReSurfX::vysen were based on gene expression measurements in biological systems. We continued to expand solutions for that class of datasets and continue to add as functionalities in the product.
Gene expression is a very powerful reporter of system state of biological systems and has numerous valuable applications in the health sector. We have demonstrated the immense power of gene expression data beyond previously known both in utility for deciphering complex insights and outcomes when AI is done right, as well as their utility as data sources to validate AI solutions. In addition other advantages included:
- The classes of datasets using different platforms of measuring system-wide gene expression represented two extremes of data-properties of most real-life data to outcome needs hence the extensibility of those powerful solutions become obvious.
- The data properties they represented offered capabilities to test core-aspects and other needs discussed here for realizing the potential of ML and AI effectively - numerically as well as through data-purpose associated information content (i.e., knowledge content).
- Solutions for effective use of datasets from this platform and numerous uses of them to improve the health sector have been developed over almost two decades with increasing breath of expertise over time from sectors beyond biomedical disciplines. Considering that, the level of improvement that we find at each stage of this example extols the exceptional increase in power and value conferred by the use of AHT based solutions.
Our approach is to develop functional modules from AHT with broad applicability as well as the ability to easily tailor-for-need. One of the application configurations we have developed by combining different stages of assembling and processing these datasets with a combination of analytics and prediction solutions we developed to get to outcomes and end-points of interest is SyRTOP (Systems Response Based Triggers and Outcomes Predictor). A pictorial outlining the SyRTOP application configuration is shown below.
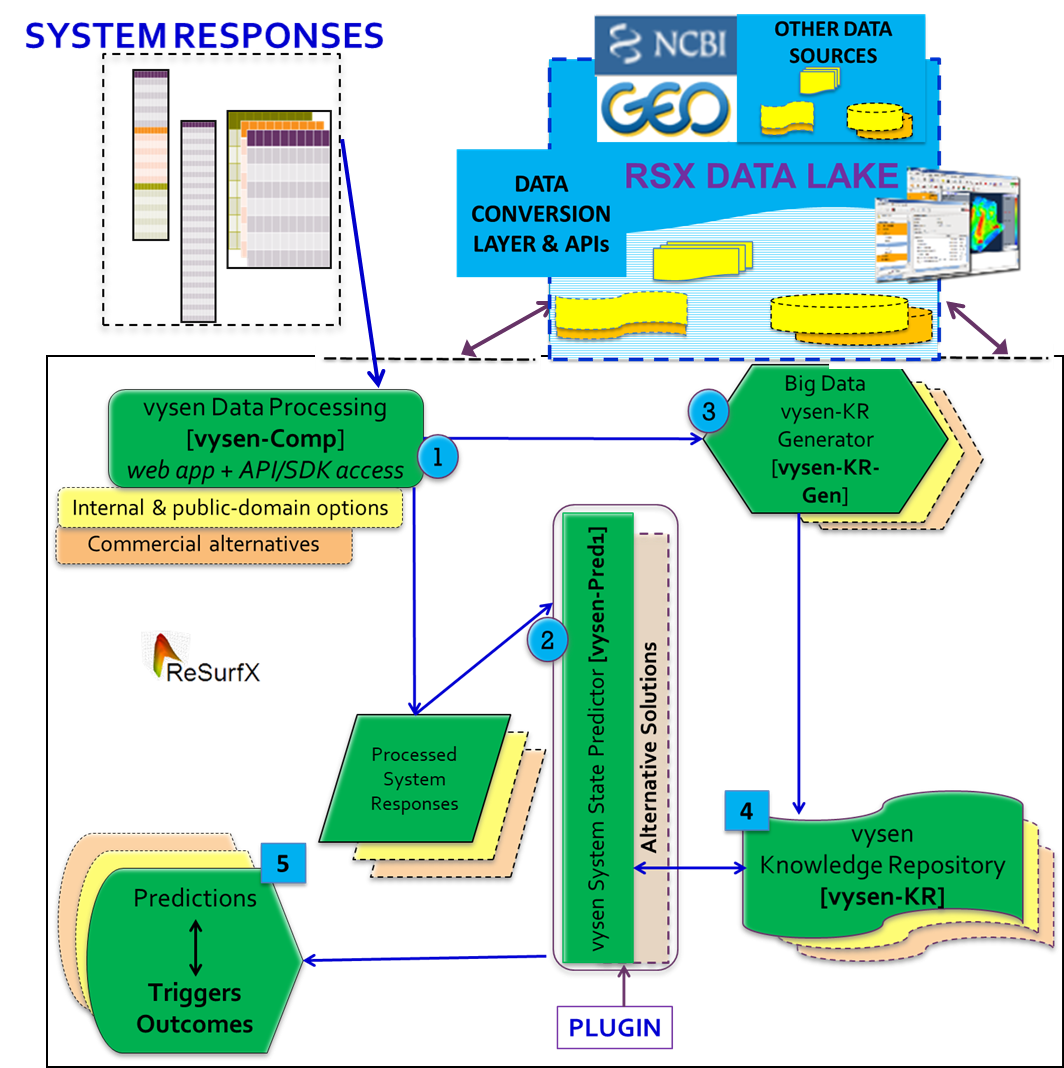
In the above figure, the original intended output are the predictions (marked as #5), a key deviation from typical machine learning based AI approaches and a powerful value add we designed to provide intermediate results as extremely accurate knowledge repositories (KRs – marked as #4). This enables our customers can use these KRs (that can be custom generated from their proprietary data as well) with extreme confidence to improve outcomes in their workflow steps that are using substandard approaches, by sheer quality of input to those steps. The use of AHT based solutions to generate KRs avoids many problems including the reason we mentioned as the primary cause of failure of IBM Watson in healthcare applications. Those KRs also becomes high quality input when used as intermediate steps of their workflows improving outcomes from other approaches used.
In a use case for SyRTOP that we have shared a lot of information from is the use of system-wide gene expression from live biological systems that start with a reasonably simple goal to predict drug classes they were treated with. Those results are elaborated in great detail in our post ReSurfX in 2021 – Best-in-class Outcome Predictors, Innovation Catalysts and ROI Multipliers. The results reveal immense power, accuracy, reproducibility of gaining not only the result we targeted by remarkably powerful insights that are difficult to get even if studies are targeted towards those insights.
At-scale tests of that use case proved that not only can SyRTOP provide accurate results towards the primary goal, but can tease our remarkably subtle properties of drugs (like biological and chemical relatedness), comorbidities etc. Such results provide compelling evidence and enormous confidence on the use of novel insights identified by SyRTOP and AHT based solutions as well. The last of those points caters to one of the key aspects of AI and digital transformation I emphasized earlier: reliability of insights is a key property for enterprise and large-scale adoption of AI solutions – else lot of resources of various kinds and can importantly manifest as time lost and cumulative effects in long development cycles.
Another surprisingly powerful class of insights we found from that use case are those that were drug-interactions identified by regulatory agencies (like USFDA) post-market surveillance – i.e., after drugs have been approved and use in large scale (Real World Data). Those interactions were so strong and important that they issued market guidance to avoid co-prescribing those drugs or label those interactions for conditions where they occur. The ability to recover several such drug-drug-interactions (DDIs) information not only depends on drugs but also depend on their drug dosage and exposure time and more factors. Such complexity captured by the AHT based solution we are developing is a remarkable testament to our approach of building modular solutions that can be used in a variety of conceptually overlapping needs in drug and med-device development and in effective patient care application. These applications empower (i) the high accumulated knowledge based manpower health sector is highly reliant on, and (ii) many sector entities with contrasting goals interacting in a complex construct in the midst lot of opportunities opened up by digital transformation the same time a major effort to transform the sector from predominantly fee-for-service to value-based system.
Other key aspects besides the use of AHT for this level of enhancement in robustness, accuracy and capability to derive more insights (and very difficult ones) included how we handled GIGO and the fact that often we resorted to developing or assembling our own metrics from concepts rather than directly using classical metrics. Some easy to follow but extensive and thorough results with important observations and conclusions related to the previous statement are in different whitepapers and blogs at resurfx.com/vysdom. The metrics we developed and used often turned out so reliable that we could use them with highly reliability for binary and multi-class separators along many useful and complex dimensions of real -life needs. That also demonstrates the value of those metrics as measure of confidence for other needs.
Observations, inferences and thoughts shared here may not represent collective conclusions at ReSurfX.
They can sometimes be context dependent.